Eine Microservice Hommage an die Unix Philosophie
Download des kompletten Tarball mit Sources & Binaries hier:
Disclaimer: Diese Prozese in der Demo MicroVM laufen intern alle root user. Das ist natürlich im späteren Produktivsystem so nicht tragbar. Beachte das. Du musst dann zusätzlich systemuser anlegen und priviledge Drop durchführen für die einzelnen services. Das sollte selbtverständlich sein! Es steht dir z.B. setuidgid oder unshare zur Verfügung. httpd bringt z.B. auch schon einen eigenen parameter -u user:group mit. Das lassen wir hier der Übersichtlichkeit halber weg. Es ist eh schon recht viel auf einmal.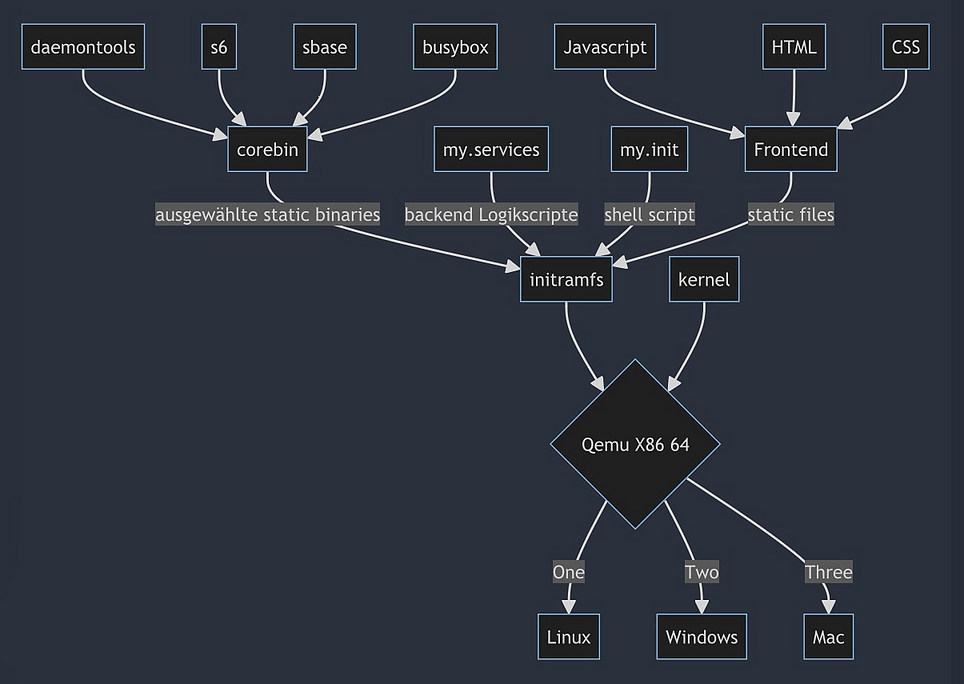
Nicht mit docker sondern als QEMU basierte MicroVM realisiert.
Dies ist eine Tech Demo. Du benötigst make, cpio und qemu-system-x86, um damit Rumzuspielen
# als root nutzer apt-get install make cpio qemu-system-x86 # als normaler systemuser wget https://finalmedia.de/code/techdemo/miniknot/miniknot.latest.tgz tar xvzf miniknot.latest.tgz cd miniknot make setup frontend make update pack run
Dann einfach einen Browser öffnen auf http://127.0.0.1:8081/
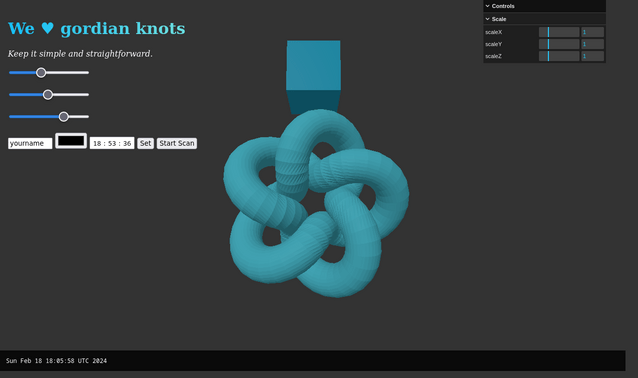
Im Frontend an den Reglern rumspielen, sowie das 3D Objekt bewegen und mit den anderen Reglern skalieren. Das Ergebnis sind Messages auf stdout.
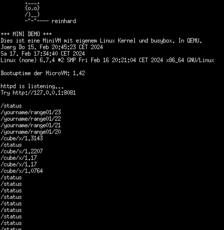 Auf dem Terminal werden aufgerufene Pfade auf STDOUT ausgegeben
Auf dem Terminal werden aufgerufene Pfade auf STDOUT ausgegeben
Wenn du im Terminal STRG+C drückst terminiert qemu. Das Frontend wird das aufgrund des Pollings merken und die Anzeige "unscharf" darstellen. Wenn du dann das Backend wieder startest mittels
make run
Dann wird das Frontend auch das wieder erkennen.
 Beim Disconnect des Backends wird das Frontend automatisch "unscharf" und blendet eine Meldung ein.
Sobald das "Backend" wieder verfügbar ist, wird die Seite wieder scharf.
Beim Disconnect des Backends wird das Frontend automatisch "unscharf" und blendet eine Meldung ein.
Sobald das "Backend" wieder verfügbar ist, wird die Seite wieder scharf.
In einem zweiten Terminal ebenso in den Ordner wechseln in dem auch diese README.md liegt, dann dort einfach ein
make benchmark
aufrufen. Es setzt curl voraus und bombadiert das Backend einfach mit Zufallsanfragen.
Konkret baut es Zufalls-Pfade im Stil: /store/c3c3388c7cf8717469ece6606b28f98c/3fe6890ad0c87340b6fc50673841ed31aff7f4b18e2e20cf3d7dc5b51fbeea28cc3144ce84939 und nutzt curl, um diese Aufzurufen.
Das funkioniert so
tr -dc "0-9a-f" < /dev/urandom # erstellt zufallsfolge mit Zeichen aus dem Bereich 0-9 a-f auf stdout fold -w 160 # liest klonend von stdin nach stdout und bricht nach 160 Zeichen mit einem newline um sed 's/./&\//32' # arbeitet pro Zeile und fügt an der Stelle 32 einen Slash / ein. sed "s|^|http://127.0.0.1:8081/store/|g" # stellt der gesamten Zeile die genannte URL als Präfix voran xargs -r -s 1024 curl -s > /dev/null # ruft mittels xargs jede fertig gebaute URL Zeile mittels curl auf
Es gibt viele weitere Tests. z.B. erzeugen wir als demo auch streams, deren Durchsatz du testen kannst. Wenn die Demo läuft kannst du daher diese Tests versuchen:
make demo-stream-random make demo-stream-yes make demo-stream-zero
Wenn du ein Audiogerät auf deiner Workstation hast und dir dort aplay zur Verfügung steht, kannst du das testen:
make demo-stream-bytebeat
Es erzeugt einen endlosen Stream, der als 8000 mono raw Audio interpretiert einen Beat widerspiegelt. Natürlich wäre das auch über das Frontend abspielbar, dann könnte der Stream auch direkt im Frontend erzeugt werden. Dies ist nur eine Demo darüber, wie sich auch Streams im Backend abbilden lassen, wenn man unbedingt auf CGI setzen möchte. Das ist aber nicht zwingend notwendig.
Es gibt einen kleinen httpd in dem minimalsystem, bestehend aus einem Linux Kernel und der Busybox. Dieser httpd ist bestandteil der Busybox und loggt auf stdout. Diese Logs werden in einer pipeline so dargestellt, dass nur die aufgerufenen Pfade dargestellt werden.
Der verwendete webserver erlaubt kein verzeichnislisting, sondern liefert nur statische Dateien aus. Minimalistisch.
Wir nutzen zum Einreichen von Informationen also auch kein GET, PUT oder POST, sondern letztlich nur einen HEAD Request, weil alle für uns relevanten Informationen im aufgerufen Pfad selbst codiert sind. Damit sind alle relevanten Informationen stets Bestandteil der URL. Wir bräuchten kein CGI. Das ist nur eine zusätzliche Demo, weil danach gefragt wurde.
Der Verzicht auf CGI und das Abbilden aller Request über Pfade hat den Charme, dass alle Information und Payload 1:1 im Log landen. (falls wir einen log führen). Du könntest GET und Query Parameter übergeben, die landen aber nicht in der Anzeige und werden auch ignoriert. Sind können dir aber z.B. für Non-Caching Forcing und Testing hilfreich sein.
Gedacht ist der Bytestream auf STDOUT derart, dass man ihn innerhalb der VM an weitere Prozesse auf deren stdin multiplexed. Diese Prozesse werten dann nur für sie jeweils relevante Pfade aus, z.B. anhand einem für sie passenden Schlüsselwort auf ersten relativen Pfad-Ebene.
Zu berücksichtigen ist die maximale Pfadlänge, sowie der Zeichenumfang.
Es wird definiert, dass nur die Zeichen 0-9 a-z A-Z . / als zulässige gelten, wobei / die Ebene kennzeichnet und somit kein Bestandteil eines value sein kann.
ein base64 encoding ist somit bewusst NICHT möglich und auch kein URL encoding.
Beispiel: Möchtest du unter diesen eingeschränkten Bedingungen eine binäre payload übertragen, musst du diese z.b. erst in chunks von 128 hexchars zerlegen 0-9a-f und dann mehrere requests durchführen. Damit man die passende zusammenführen kann, definierst du z.B. eine uuid.
Auf dem System hast du dann wiederum z.B. einen prozess, der diese request akkumuliert, in eine Datei Zeile für Zeile wegschreibt, dir die möglichkeit zum crc check gibt und die daten dann von ascii hex encoding nach binary umschreibt. Das ist ein universelles Konstrukt, dass du dann in vielen Funktionen später nutzen kannst, weil du selbst auf der clientseite (also im Frontend) den zielnamen über deine uuid vorgibst. So ein Beispielpfad kann also sein
/store/b2ca2220cdb911eeafa1c771c18b8a85/9f2daac803ff89aaaf2613fe977b0a41f3ca077dc....
dein frontend/client definiert also zunächst selbst eine uuid, in obigem Fall b2ca2220cdb911eeafa1c771c18b8a85 und sendet dahin eine payload, die da wäre 9f2daac...
der prozess der die logs/messages mitliest, erkennt am /store/ dass er gemeint ist. er sieht weiterhin "b2ca2220cdb911eeafa1c771c18b8a85" und legt eine Datei an, die diesen Namen trägt... und schreibt als append den content hinein, der mit dem 9f2daac... beginnt. wobei er dem dateinamen ein entsprechenden zielverzeichnisname voranstellt.
also dieser gesamte Prozess ist eigentlich nichts weiter als dieser Einzeiler:
grep -oE "^/store/([0-9a-f]*)/([0-9a-f]*)" | awk -F'/' '{ print $4 >> "/var/www/store/" $3 }'
Dieser Ansatz ist effizient, weil er die Eingabezeile in einem single pass prozessiert. Er vermeidet es, die Zieldatei mehrfach zu prozessieren, oder ein komplexes Programm in C, python o.ä dafür zu schreiben. Zudem sind grep und awk sehr performant, extrem robust und out-of-the-box hier verfügbar.
awk hält dabei aber file Handles offen. je nach Umgebung und Einsatzzweck willst du das nicht, da du sonst irgendwann den Fehler "Too many open Files" erhalten würdest. Diese Filehandles sollten daher noch geschlossen werden, was jedoch die Performance dann etwas verschlechtert, wenn in eine Datei viele Zeilen auf einmal geschrieben werden sollte. In jedem Fall sieht der Einzeiler final dann wie folgt aus:
grep -oE "^/store/([0-9a-f]*)/([0-9a-f]*)" | awk -F'/' '{ file = "/var/www/store" $3; print $4 >> file; close(file); }'
Der Speicherort ist so gewählt, dass du mit einer webabfrage die geschriebene datei direkt prüfen kannst, da du ja selbst den gewählten dateinamen kennst. Und "Fremddateien" von parallelen Anfragen anderer Clients sind nicht gelistet, da der Webserver kein Verzeichnislisting unterstützt. du müsstest also die uuid eines anderen request erraten oder wissen, um dessen Content zu verändern oder zu lesen.
Beispiel. Wenn du mit
http://127.0.0.1:8081/store/abc/12345 http://127.0.0.1:8081/store/abc/bbbbb
Den Wert 12345 in die Die Datei /var/www/store/abc an geschrieben hast, und den Wert bbbbb als zweite Zeile in der gleichen Datei ergänzt hast, kannst du via aufruf auf
http://127.0.0.1:8081/store/abc
Diese Datei ausgeben und damit beide Zeilen auch sehen und prüfen.
Eine Datei wird nicht gelöscht. Dafür würdest du einen anderen Prozess definieren.
Es gibt zwei Ansätze. Entweder du gestattet direktes Löschen, was aber eine Command Injection ermöglichen könnte und auch ein separates Recht wäre... oder du sorgst dafür, dass awk einfach ein nullbyte file schreibt und ein separater prozess diese periodisch aufräumt. Letzteres bietet sich an, weil du damit auch gleich einen "clear" realisiert hast, um eine Datei wieder zu leeren. Unser Einzeiler verändert sich dadurch nur minimal:
grep -oE "^/clear/([0-9a-f]*)/([0-9a-f]*)" | awk -F'/' '{ file = "/var/www/store" $3; printf "" > file; close(file); }
Wir schreiben also einen empty string in die Datei, statt append. Und als Schlüsselwort Task haben wir "clear" statt "store" definiert.
Ein Prozess der asynchron alle Nullbyte files dann periodisch aufräumt könnte einfach ein cronjob wie dieser sein
find /var/www/store/ -type -f -size 0 -delete
Er wird dann auch nicht durch einen Webaufruf ausgelöst, sondern findet z.B. periodisch im System selbst statt.
Beachte bei der grep | awk Zeile, das dass Buffering der Pipeline entscheidend ist. Es muss auf line buffer umgestellt sein, oder generell buffering abgeschaltet sein, damit du direkt eine Ausgabe zu Eingabge sieht.
dafür gibt es bei dynamisch gelinkten binaries normalerweise die Befehle "stdbuf -i0 -o0" die man voranstellt. Das arbeitet mit einem LD_PRELOAD und injected eine .so und entsprechende Umparametrisierung. Idealweise baut man für den Einsatzzweck aber bereits die binaries so, dass das Problem nicht auftritt, also schon das Buffering optimiert ist.
Die busybox Version von grep hat leider (im Gegensatz zu coreutils "originalversion") keinen Parameter, um auf linebuffered umzustellen. Daher gibt an die awk line erst Daten weiter, wenn der Buffer gefüllt ist, damit wird das auch erst verzögert prozessiert.
Du siehst das z,B, wenn du den Benchmark ausführst. Da tauchen deswegen Zeilen auf, weil wir den STDIN mit vielen Zeilen fluten.
Im Produktiveinsatz würde man also nicht die busybox grep Version nutzen. Gleiches gilt für die Ausführung von awk. Für diese Techdemo reicht jetzt aber einmal die busybox Variante, um die Thematik nicht zu unübersichtlich zu gestalten.
Update: Es wurde unbuffered_grep, unbuffered_cut und unbuffered_tr ergänzt. Diese stammen aus den sbase suckless https://core.suckless.org/sbase/ und wurden dahingehend gepatched, dass vor der main() function jeweils ein
setbuf(stdout,NULL); setbuf(stdin,NULL);
aufgerufen wird. Diese Varianten arbeiten also mit abgeschaltetem Buffering.
Generell ist die coreutils Umsetzung von suckless sehr empfehlenswert. Hinter den Arbeiten steckt Laslo Hunhold
Wenn du schon immer mal was mit rust machen wolltest und dich cargo nicht abschreckt: https://github.com/uutils/coreutils/wiki ist ein Nachbau der coreutils komplett in rust.
Klar. Passe die Makefile an im bereich "run". Dort gibst du qemu statt den definierten 64MB RAM dann mittels -m 1024m z.B. einfach 1024 MB RAM. Sollte inuitiv sein.
Das ist wichtig, damit qemu nicht noch zuvor einen pxe boot versucht. Das würde dich auch einige Sekunden Bootzeit kosten. Und natürlich wollen wir ja keinen Netzwerkboot, sondern eben boot des Kernels und des initramfs.
make run 2>&1 | grep "^/test/range02/2."
Würde nur auf den zweiten Regler reagieren, im Wertebereich 20 und aufwärts und nur, wenn du im Eingabefeld bei "yourname" auch "test" eingegeben hast.
Und das grep läuft dabei nicht in der VM sondern auf deinem System. Konkret... du spielst an den Reglern, das sind http requests in die VM, dortiger httpd schreibt auf stdout und qemu läuft bei dir ebenso, dass es auf stderr schreibt, was du nach stdout umbiegst und dann, bei dir wieder und filterst.
Daher funktioniert auch das
stdbuf -i0 -o0 make update pack run 2>&1 | \
stdbuf -i0 -o0 grep -o -E "^/store/([0-9a-f]*)/([0-9a-f]*)" | \
stdbuf -i0 -o0 awk -F'/' '{ print $4 >> "/tmp/" $3; print $0; fflush(); }'
Wenn du Daten aus der VM raustragen willst und auf deinem System unter /tmp/ speichern willst. Dann genügt ein Aufruf von http://127.0.0.1/store/abcd123/bbbbbbbbbbb9999
und du findest (auf deinem Rechner! unter /tmp) die Datei "abcd123" mit dem Inhalt bbbbbbbbbbb9999
Einfach in der my.init Dinge anpassen oder in dem Verzeichnis initramfs/ beliebige Anpassungen vornehmen. Danach genügt im Hauptverzeichnis wieder ein
make update pack run
Ja, du kannst das hier aufrufen und damit zur Ursprungsdemo zurückkehren. Bedenke aber, dass du dann deine eventuellen Änderungen am Frontend verlierst.
make clean setup frontend update pack run
Nicht in der jetztigen Konfiguration und Demo. Die läuft ja im RAM. Aber natürlich kann man auch virtuelle Laufwerke oder ein 9P Filesystem (virtiofs) durchreichen, ebenso nbd Laufwerke etc. dann auch direkt im Hypervisor. Da gibt es viele Möglichkeiten. Auch innerhalb der VM.
Klar. Du hast ja im Gegensatz zu Docker hier nen vollen eigenen Linux Kernel unter deinen Händen. Es geht Wireguard. VXLAN. All yours!
Du kannst damit auch eine von qemu unabhängige hardware bootfähige Variante erstellen. Passe den Kernel an, dass er deine Hardware unterstützt. Und nutze z.B. syslinux. Damit kannst du ein wenige MB großes System erhalten, das ebenso in wenigen Sekunden gebootet ist.
Auch ein EFI Boot wäre denkbar, wenngleich nicht unbedingt sinnvoll. Und natürlich kannst du auch auf anderen Systemarchitekturen qemu-system-x86_64 ausführen, z.B. auf einem raspberry pi, arm64, riscv etc. natürlich mit etwas mehr overhead.
dein Linux Kernel und das gesamte emulierte System läuft damit auch unter Windows.
Nuitka ist ein ebenso in Python geschriebener Transpiler. Er bringt deinen python code zu c code, den du wiederum als statische binary und ohne abhängigkeiten compilieren kannst. Nuitka kann damit Binaries für Windows, macOS, Linux, and FreeBSD/NetBSD erzeugen.
nuitka --standalone --static deinpython.py
Allerdings würde ich dazu raten, diese Herangehensweise zu überdenken. Oft können die Aufgaben in Einzelteile heruntergebrochen werden und sind in Einzeiler mit Bordmitteln bereits realisierbar.
In der Unix-Philosophie schreibst du Programme als Filter. Sie haben eine Aufgabe und sollen diese möglichst gut machen. Sie sollen nicht komplex sein, sondern gut testbar, indem man alle erdenklichen inputs auf sie wirft und da Ergebnis auswertet. Das kannst du nur tun, wenn du modular arbeitest und die Komplexität der einzelnen Aufgabe extrem reduziert.
In python neigst du dazu, viele libraries zur laufzeit dazu zu laden, selbst um einfache Dinge zu erreichen. Das ist schlechter Stil und entspricht nicht der Unix Philosophie und nicht dem KISS Prinzip.
Wenn du Scripten willst, verwende besser eine statisch gebaute Version von lua
Zudem bietet ich auch quickjs von Bellard an, wenn du Javascript auch im Backend bevorzugst.
quickjs lässt z.B. auf eine statisch gelinkte Binary bauen, die unter 1MB bleiben wird.
Ich habe hier schon busybox und einen kernel vorgebaut. Natürlich wirst du das aber auch selbst machen wollen, um auch dafür deine eigene pipeline zu bauen. Ich gehe davon aus, dass du auch auf x86 baust und kein crosscompile nötig ist und du über einen debian oder Ubuntu Distri verfügst, auf der du das hier liest. Dann genügt das hier
Dazu brauchst du build essentials, flex bison etc.
apt-get install build-essentials flex bison ncurses-dev
Meine Kernel config für das aktuelle Beispiel findest du in my.kernel.config im tarball
wget https://cdn.kernel.org/pub/linux/kernel/v6.x/linux-6.7.5.tar.xz tar xvf linux-6.7.5.tar.xz cd linux-6.7.5 cp my.kernel.config linux-6.7.5/.config cd linux-6.7.5 make -j4 cp arch/x86/boot/bzImage ../bzImage cd ..
wget https://busybox.net/downloads/busybox-1.36.1.tar.bz2 tar xvfj busybox-1.36.1.tar.bz2 cd busybox-1.36.1 make menuconfig make-> statische gelinkte version bauen und all das anwählen, was du haben willst. Es fällt dann eine busybox binary heraus. Die auch nach ../busybox kopieren. In der hiesigen Demo ist prinzipiell alles angehakt und mitgebaut außer dem dhcpc.
Meine Makefile
setup:
mkdir -p initramfs/command
cp busybox initramfs/
cp -r command initramfs/
cp my.init initramfs/init
cp my.services initramfs/setup
chmod +x initramfs/init
chmod +x initramfs/setup
frontend:
tar -C initramfs/ -x -v -z -f my.frontend.tgz
date > initramfs/label
update:
cp -r command initramfs/
cp my.init initramfs/init
cp my.services initramfs/setup
chmod +x initramfs/init
chmod +x initramfs/setup
rm -rf initramfs/boot
mkdir -p initramfs/boot
find . -name "my.boot.*.sh" -exec cp "{}" initramfs/boot/ \;
pack:
cd initramfs && find . | cpio -ov --format=newc | gzip -9 > ../initramfs.img.gz
run:
qemu-system-x86_64 -enable-kvm -cpu host -m 512m -kernel bzImage -initrd initramfs.img.gz \
-append "earlyprintk=ttyS0 console=ttyS0" -nographic -nodefaults -no-user-config \
-serial stdio -monitor none -sandbox on -netdev user,id=n1,restrict=on,hostfwd=tcp::8081-:80 \
-device virtio-net-pci,romfile=,netdev=n1
clean:
rm -rf initramfs
rm -rf initramfs.img.gz
# benchmarks and demos need additional tooling: curl, hd, aplay, pv
store-benchmark:
tr -dc "0-9a-f" < /dev/urandom | fold -w 160 | sed "s|.|&/|32" | sed "s|^|http://127.0.0.1:8081/store/|g" | xargs -r -s 1024 curl -s > /dev/null
benchmark:
tr -dc "0-9a-f" < /dev/urandom | fold -w 160 | sed "s|.|&/|32" | sed "s|^|http://127.0.0.1:8081/no/|g" | xargs -r -s 1024 curl -s > /dev/null
benchmark-streaming:
curl -s http://127.0.0.1:8081/cgi-bin/stream-zero | pv > /dev/null
demo-stream-yes:
curl -s http://127.0.0.1:8081/cgi-bin/stream-yes
demo-stream-random:
curl -s http://127.0.0.1:8081/cgi-bin/stream-random | hd
demo-stream-zero:
curl -s http://127.0.0.1:8081/cgi-bin/stream-zero | hd
demo-stream-bytebeat:
curl -s http://127.0.0.1:8081/cgi-bin/stream-bytebeat | aplay
Meine my.init
#!/busybox sh
/busybox mkdir -p bin sbin dev etc home root mnt proc sys var/www var/log /usr/bin /service /srv
/busybox --install
mknod /dev/null c 1 3
mknod /dev/zero c 1 5
mknod /dev/console c 5 1 2>/dev/null
mknod /dev/urandom c 1 8
mknod /dev/full c 1 9
mount -o hidepid=2,nosuid,nodev,noexec,relatime -t proc none /proc
mount -o nosuid,nodev,noexec,relatime -t sysfs none /sys
export PATH=/command:/usr/local/bin:/usr/local/sbin:/bin:/sbin:/usr/bin:/usr/sbin
# Info
(
echo ICAgICAgICAuX19fLgogICAgICAgIHtvLG99CiAgICAgICAgLylfXykgICAgIAogICAgICAgIC0iLSItLS0tIHJlaW5oYXJkCgo= | base64 -d
echo "+++ MINI DEMO +++"
echo "Dies ist eine MiniVM mit eigenem Linux Kernel und busybox. In QEMU."
test -f /label && cat /label
uname -a
echo
echo -n "Bootuptime der MicroVM: "
cut -d " " -f1 /proc/uptime
echo
echo "Try http://127.0.0.1:8081"
echo
) | tee /etc/motd /var/www/status
# setup network
ip a add 10.0.2.15/24 dev eth0
ip link set eth0 up
ip route add default via 10.0.2.2
# general setup
/setup
# setup daemontools
/command/svscanboot &
#ln -s /var/log/httpd/current /var/www/httpd.log
#ln -s /var/log/cleard/current /var/www/cleard.log
#ln -s /var/log/stored/current /var/www/stored.log
exec watch -t -n 8 "(cat /etc/motd; date; echo; free; echo; find /srv/ -mindepth 1 -maxdepth 1 -type d -exec svstat \"{}\" \; ;echo; tail -n 4 /var/log/httpd/current) | tee /var/www/status.tmp && mv /var/www/status.tmp /var/www/status"
#exec /bin/sh
#exec tail -n 0 -F /var/log/httpd/current 2>/dev/null
und meine my.services in der die daemon services für die daemontools definiert werden
#!/bin/sh
# run additonal bootup scripts (if exists)
# do this before setup
test -d /boot && find /boot -type f -exec sh "{}" \; &
# SERVICES
## httpd
mkdir -p /srv/httpd
cat << ::EOF:: > /srv/httpd/run
#!/bin/sh
exec 2>&1
mkdir -p /var/www
exec httpd -h /var/www/ -f -p 80 -vv 2>&1 | unbuffered_cut -d: -f7- | unbuffered_grep "^/"
::EOF::
## stored
mkdir -p /srv/stored
cat << ::EOF:: > /srv/stored/run
#!/bin/sh
exec 2>&1
mkdir -p /var/www/store
#mount -t tmpfs -o size=20M storage /var/www/store/
exec tail -n0 -F /var/log/httpd/current | unbuffered_grep -E "^/store/([0-9a-f]*)/([0-9a-f]*)\$" | awk -F'/' '{ file = "/var/www/store/" \$3; print \$4 >> file; close(file); print \$0; fflush(); }' | tai64n
::EOF::
## cleard
mkdir -p /srv/cleard
cat << ::EOF:: > /srv/cleard/run
#!/bin/sh
exec 2>&1
exec tail -n0 -F /var/log/httpd/current | unbuffered_grep -E "^/clear/([0-9a-f]*)" | awk -F'/' '{ file = "/var/www/store/" \$3; printf "" > file; close(file); print \$0; fflush(); }' | tai64n
::EOF::
## AUTOGENERATE ALL LOG DAEMONS
find /srv/ -mindepth 1 -maxdepth 1 -type d | sed "s|^/srv/||g" | while read name
do
mkdir -p "/srv/${name}/log"
cat << ::EOF:: > "/srv/${name}/log/run"
#!/bin/sh
exec 2>&1
mkdir -p "/var/log/${name}"
exec multilog n2 s2000000 "/var/log/${name}/" >/dev/null
::EOF::
done
## MAKE ALL RUN FILES EXECUTABLE
find /srv/ -type f -name "run" -exec chmod +x "{}" \;
## ACTIVATE ALL DAEMONS
find /srv/ -type d -mindepth 1 -maxdepth 1 -exec ln -s "{}" /service/ \;
Nachtrag: Auf Rückfrage hier auch ein Beispiel wie man mit dem busybox httpd dynamischen Content ausliefern kann und auch Streaming realisieren kann. (Da gibt es viele Möglichkeiten). Standarmäßig erlaubt der busybox httpd die Ausführung von Scripten als CGI, wenn diese mit chmod +x ausführbar gemacht wurden und wenn sie im Verzeichnis /cgi-bin/ liegen. Das nutzen wir also für eine weitere Demo:
Daher hier meine my.boot.cgi.sh, in der ich nun (optional) eben noch CGI Services zum Streamen definieren, sieht so aus:
#!/bin/sh
## NON PATH STANDARD CGI (IF WANTED AT BOOTTIME)
## Dienst als Demo von Streaming Prozessen
## und generell dynamischem Content
mkdir -p "/var/www/cgi-bin"
cat << ::EOF:: > "/var/www/cgi-bin/stream-random"
#!/bin/sh
/bin/echo -e -n "Content-Type: application/octet-stream\n\n"
/bin/echo -e -n "Cache-Control: no-cache\n\n"
exec /bin/cat /dev/urandom
::EOF::
cat << ::EOF:: > "/var/www/cgi-bin/stream-zero"
#!/bin/sh
/bin/echo -e -n "Content-Type: application/octet-stream\n\n"
/bin/echo -e -n "Cache-Control: no-cache\n\n"
exec /bin/cat /dev/zero
::EOF::
cat << ::EOF:: > "/var/www/cgi-bin/stream-yes"
#!/bin/sh
/bin/echo -e -n "Content-Type: application/octet-stream\n\n"
/bin/echo -e -n "Cache-Control: no-cache\n\n"
exec /bin/yes
::EOF::
cat << ::EOF:: > "/var/www/cgi-bin/stream-bytebeat"
#!/bin/sh
/bin/echo -e -n "Content-Type: application/octet-stream\n\n"
/bin/echo -e -n "Cache-Control: no-cache\n\n"
/command/bytebeat
::EOF::
cat << ::EOF:: > "/var/www/cgi-bin/echo-env"
#!/bin/sh
/bin/echo -e -n "Content-Type: text/plain\n\n"
/bin/echo -e -n "Cache-Control: no-cache\n\n"
exec /bin/env
::EOF::
## ALLOW EXECUTE FOR ALL CGI BINARIES
find /var/www/cgi-bin/ -type f -exec chmod +x "{}" \;
Wie du siehst, baue ich die initramfs nicht vollständig, sondern erst zur Laufzeit. Die mknod werden also nicht vorhher nötig, sondern direkt beim boot erzeugt. Das macht das Ausrollen einfacher
Da ich qemu als net user mit NAT betreibe würde qemu einen dhcp lease verteilen. Default wäre dieser Netzbereich. Ich setze die IP also beim Bootup statisch. Damit funktioniert auch das portforwarding von Gast zu Host. BTW. der Gast darf nicht ins Internet, weil qemu netdev mit
restrict=onkonfiguriert ist.